Safely storing input data for AI pipelines

When I run AI pipelines, I often pull data from external sources, whether that’s from a proper data service, or data I scraped from a website. I’m a control freak, and this makes me nervous, because it adds a big dependency on an external source I have no control over. There’s no guarantee that if I try and rerun the same pipeline, the underlying data will still be available. Even if it is, there’s a risk that the data it returned tomorrow will be different than the data returned today. I want my own copy of the data, and when I make tweaks to the pipeline, I want to use my own copy.
This basic idea of a materialized view1 is old, and it comes with some complications. There are many ways to achieve this, and a good place to start with is to think through the requirements. In may case, I’m the only person accessing this data, so for me:
I don’t need to access the data frequently. I may go days or longer between running a given pipeline.
I’m only using this data for myself, in a single process, so I don’t need to worry about concurrency problems like reads happening before writes complete.
After I’ve stored the data, I want to be able to access it even if my machine dies.
I want the materialized format to be consistent for all the data I save. By that, I mean, I don’t want to store the data in CSV for some cases, JSON for others, and so on.
I’d like the materialized data to be compact, to keep my storage costs low.
I want to “remember” what parameters I used to pull the data with, in case I want different variations of the same data for different pipelines.
I’d like to be able to survive losing my machine without losing the data.
If for some reason I lost the materialized data, I want to be able to rematerialize it as long as the underlying data source is still available, because it’s better than nothing.
I’d like some ability to evolve my approach, if I did start bringing in other collaborators.
Because of the infrequent access, files are a nice way to store the data. I could consider a more “proper” database solution, but that adds unnecessary overhead, like the need to have a process running that does nothing most of the time. Also, versioning is non-concern, since I really want the data to be immutable.
Avro2 makes a nice choice of file format. Like CSV it can be used to store tabular data, and like JSON, it can also be used to store hierarchical data. Avro’s binary format is more compact than JSON and CSV, which is helpful for keeping the data compact. Protocol buffers3 or Thrift4 could be used in place of Avro. I chose Avro, since I’m working with Python, and since Avro doesn’t require code generation, which is fairly clunky when working in a dynamically-typed language like Python.
It’s important that the stored data is safe against a crash on my local machine. Because I have an iCloud account and I’m running on a Mac, I’m currently just storing the files in iCloud5. I could just as easily store the files in another distributed file storage system, like Amazon S36. The astute reader might notice that storing my files with a 3rd party violates the whole motivation I had in the first place, which was to reduce the 3rd-party dependency. While this is technically true, my data is realistically safer in a cloud file system than on my local machine, since these systems implement redundancy. This is a risk I’m willing to accept.
One thing I need is a way to keep track of all the files I’ve stored locally, and what parameters I used to grab the data. For this I create a “registry” to track:
The data source. I use a unique key to index the type of data I’m loading. If I’m downloading temperature data from the National Weather Service, this type might be something like
temperature.nws.Parameters. The parameters will be data-source dependent. For the temperature data for instance, the parameters might be
start_date,end_date, andcity.File location. This is where the data is actually stored.
I store the entire registry in a JSON file. JSON affords me the same flexibility as Avro, and is easier to debug if something goes wrong. Since I expect the meta-data in the registry to be small relative to the data stored in Avro files, I’m not worried about the extra storage overhead it adds on top of a more compressed format.
Implementation
I created a DataRegistry class that’s responsible for managing the registry. It has two main methods, register and mark_written. The register method is used to register a file for storage, or find a file if one has already been written:

The mark_written method is used to notify the registry that the file has been successfully written to the given location:
The reason for separating these two steps is to handle failures when trying to write data. A client of the registry:
Calls register to see if the file has already been written for the given key, schema, and data-provider-specific parameters.
If the file has not been written, the client now owns the right to write the file.
The client writes the file, and updates the registry to mark the file as written. This way later clients can know that they can safely read the data from the cache or not.
This logic is a bit subtle. To avoid having to think about it more than once, I created an abstract helper class DataProvider, which has a concrete method called cached_read that retrieves the records from the local cache if they exist, or adds them to the local cache if they don’t exist. Concrete subclasses only need to specify how to retrieve records for the first time. This is an example DataProvider subclass:
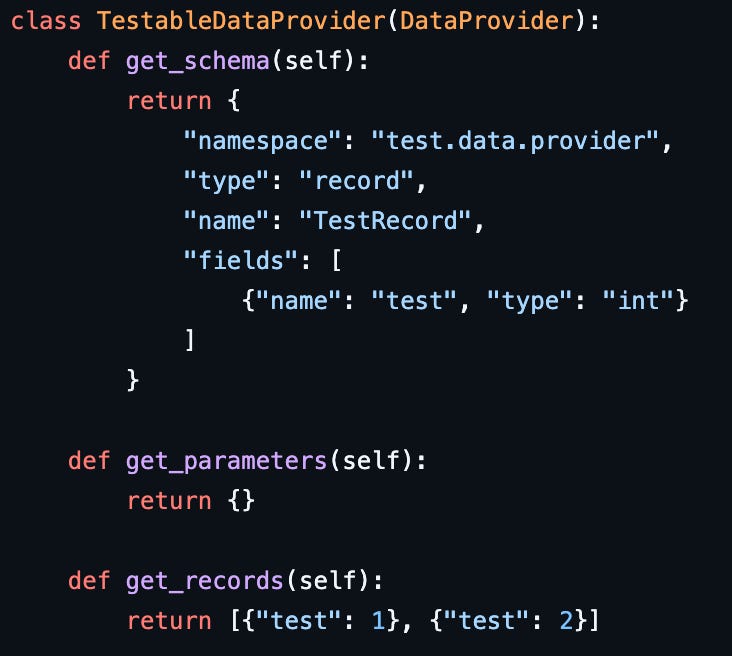
get_parameters would return something non-trivial if the same data could be retrieved with different parameters, like different time stamps. get_records can return an iterator, and in particular not necessarily a list. This can be useful for retrieving large data sets, where it may not be possible to store the entire data set in memory at once.
The full code for this post can be found in my GitHub repo.
Scaling up to multiple users
As I mentioned, this approach was built just for me. There are some elements of this design which can scale up fairly easy to multiple users. First, as long as the “local” storage is a distributed file system shared with multiple users, there’s no problem having multiple users read from the stored data.
Scaling the registry to multiple users is a bit harder. Rather than storing the entire registry in a single JSON file, it would scale better to have one registry document per key, to limit access collisions. A document database like MongoDB7 can work well for this scenario, since it can provide read-write locking on a per-key basis out of the box. At the cost of running a document database, the solution generalizes fairly well to a multi-user scenario. There’s also a need for a distributed lock, to handle the case when two writers are trying to write to the same file at the same time.
Finally, because the underlying data is stored in Avro, I have flexibility to work with teammates that are using languages other than Python. Most major programming languages have a library to read and write Avro files.
Frank Wm. Tompa, JoséA. Blakeley, Maintaining materialized views without accessing base data, Information Systems, Volume 13, Issue 4, 1988, Pages 393-406, ISSN 0306-4379, https://doi.org/10.1016/0306-4379(88)90005-1.
Apache Avro. April 18, 2025. Apache Avro™ 1.12.0 Documentation. Apache Avro. https://avro.apache.org/docs/1.12.0/
Protocol Buffers. 2025. Protocol Buffers Documentation. Protocol Buffers. https://protobuf.dev/
Apache Thrift. Apache Thrift Documentation. Apache Thrift. https://thrift.apache.org/docs/
Apple. iCloud. Apple. https://www.icloud.com/
Amazon. Amazon S3. Amazon. https://aws.amazon.com/pm/serv-s3/
Mongo DB. What is a Document Database? Mongo DB. https://www.mongodb.com/resources/basics/databases/document-databases