Datasets & Dataloaders & DataFrames
Oh my!

When starting out with PyTorch1, one of the first things you have to get your head around are Datasets and Dataloaders2. The names of these two classes are unintuitive, but basically:
A Dataset is an object used to access samples from your data set.
A Dataloader is an object used to batch samples together.
I probably would have named these classes DataAccessor and DataBatcher, to make it more clear what they do, but the key thing to remember is that you need a Dataset to tell PyTorch how to access your data, and a Dataloader to tell PyTorch how to convert samples into batches for training and inference.
To show how this works in practice, I downloaded the Intel Image Classification dataset from Kaggle3 to my local machine. I created ImageDateset to read the images from my local directory:
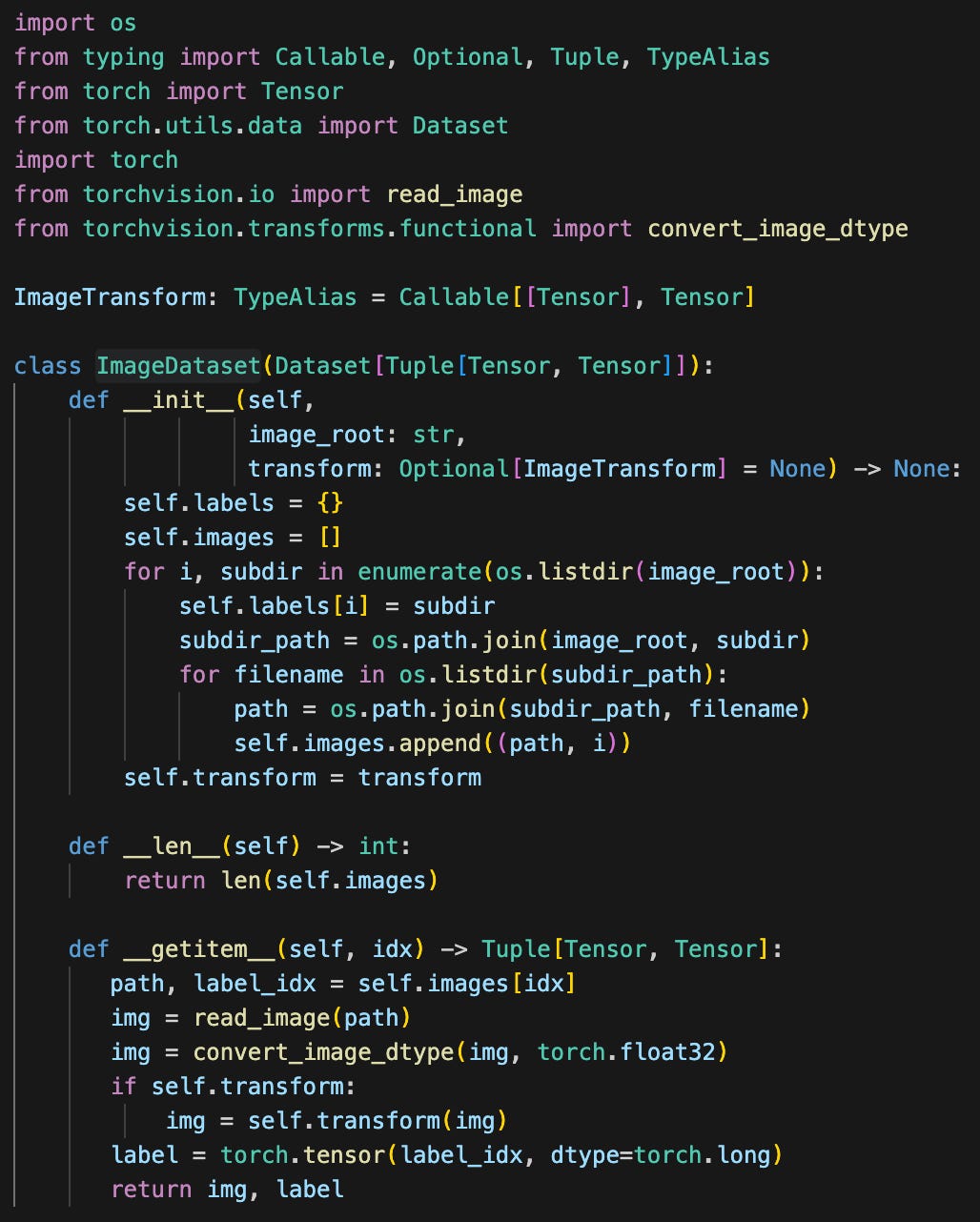
The key methods are __len__, which tells PyTorch how many images I have, and __getitem__, which returns an image and its label. For this data set, there are only six labels, which are derived from the subdirectory that contained the image. While not something you’d typically do in PyTorch, you can work with this ImageSet object directly:
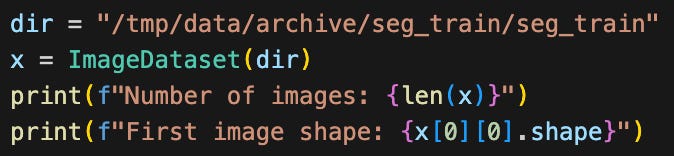
Number of images: 14034
First image shape: torch.Size([3, 150, 150])Note that each image dimension is 3 ⨉ 150 ⨉ 150. The first dimension corresponds to color channel: red, green, and blue. The second two dimensions are a 150 ⨉ 150 intensity grid for each color channel in the image.
I can now wrap this in a Dataloader to produce image batches:
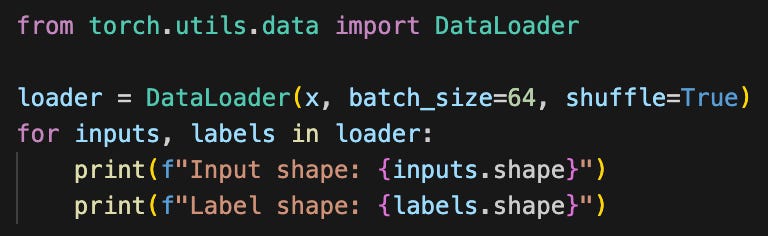
Note that the first time I ran this, I ran into a problem:
RuntimeError: stack expects each tensor to be equal size, but got [3, 150, 150] at entry 0 and [3, 103, 150] at entry 37The problem is that there’s at least one image which is smaller than the others. I can make a simple transformation to pad all images to have width and height exactly 150:
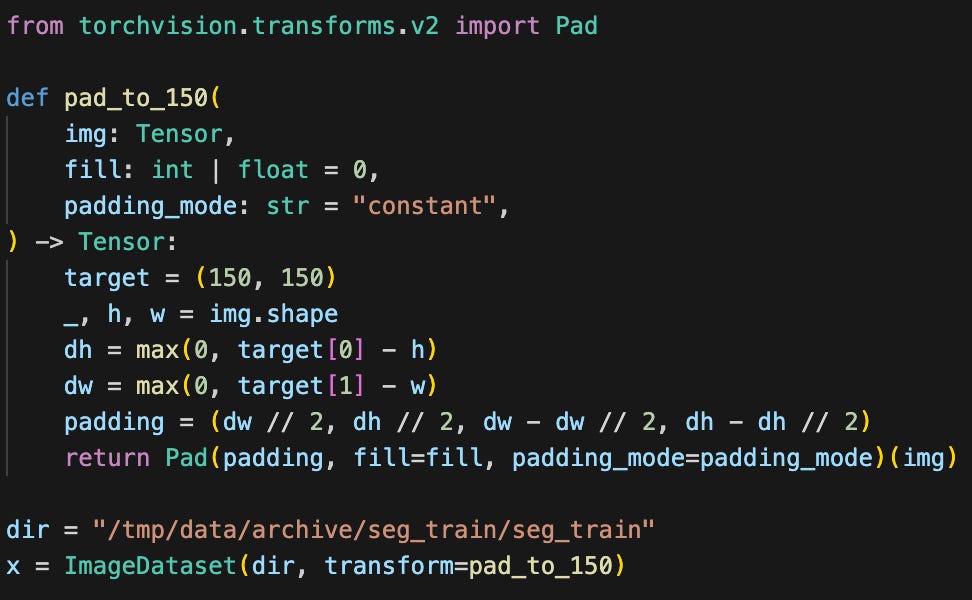
Now instead of an error I get:
Input shape: torch.Size([64, 3, 150, 150])
Label shape: torch.Size([64])
Input shape: torch.Size([64, 3, 150, 150])
Label shape: torch.Size([64])
...
Input shape: torch.Size([64, 3, 150, 150])
Label shape: torch.Size([64])
Input shape: torch.Size([18, 3, 150, 150])
Label shape: torch.Size([18])Note that the input shape for all but the last batch is 64 ⨉ 3 ⨉ 150 ⨉ 150. Here, 64 is the batch dimension. I’m batching 64 examples at a time. The very last batch is smaller, with just 18 samples, because the total number of samples wasn’t evenly divisible by 64. If this is undesirable I can set the drop_last argument of Dataloader to True to drop the last batch.
And DataFrames, Oh My!
DataFrames aren’t a thing in PyTorch, but come instead from the Pandas4 data analysis library. A DataFrame5 is an in-memory representation of tabular data, like what you might read from a database or CSV file. I often find myself starting with a DataFrame at the beginning of my AI pipeline. Because I do this so often, I’ve created a helper class called RowAccessor, which converts a DataFrame to a Dataset:
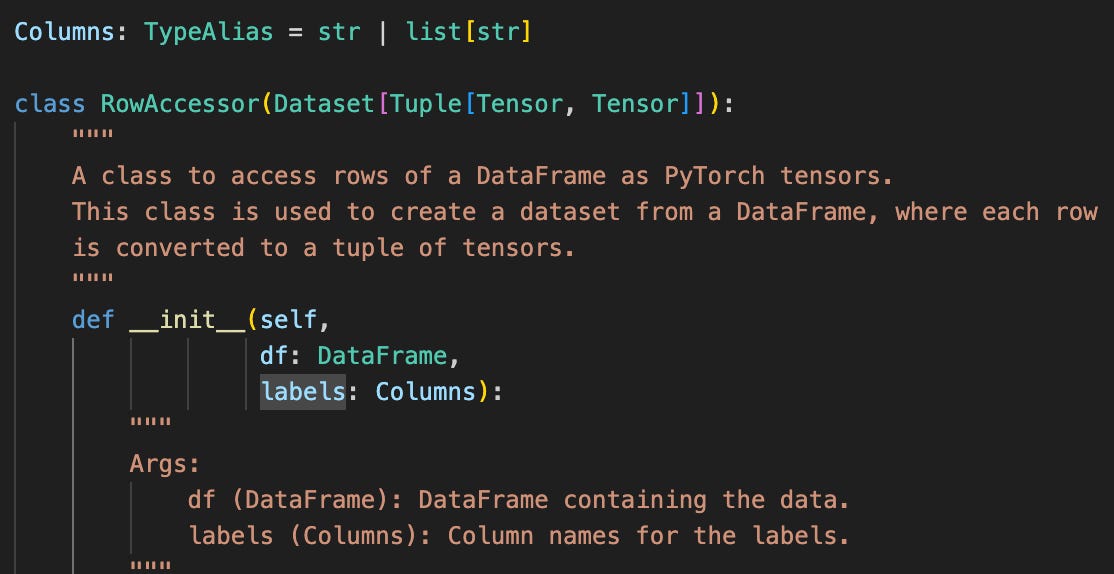
It takes a DataFrame and a list of label columns as input:
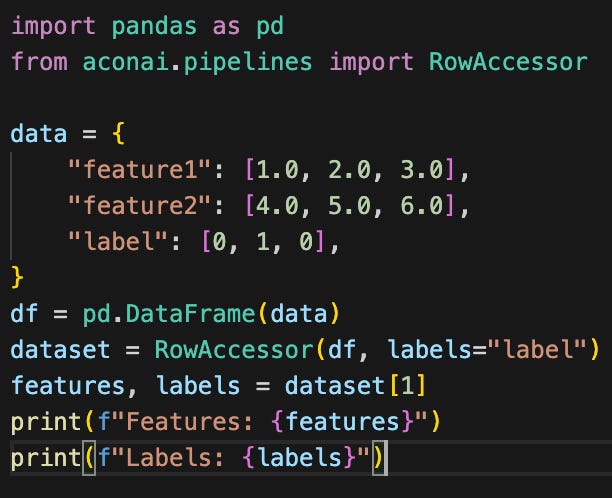
Features: tensor([2., 5.], dtype=torch.float64)
Labels: tensor([1])If I need to preprocess a DataFrame to get to it ready for PyTorch, I do this before creating the RowAccessor. So if I start with a DataFrame like this:
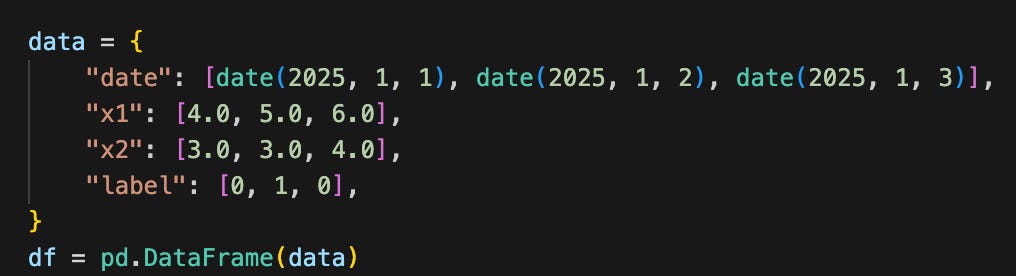
And I want to make one-hot encoded6 features for the day of the week in the date column and drop the x2 column, I would do something like this:
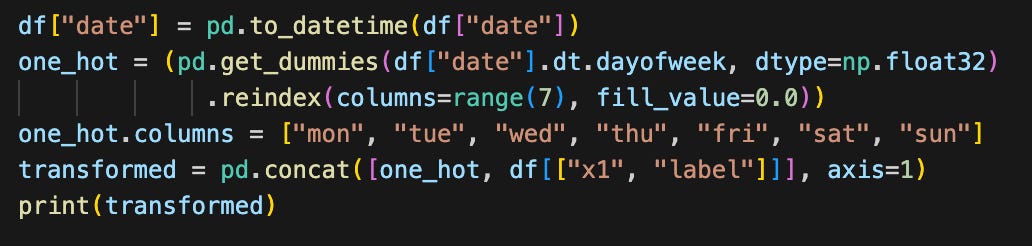
mon tue wed thu fri sat sun x1 label
0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 4.0 0
1 0.0 0.0 0.0 1.0 0.0 0.0 0.0 5.0 1
2 0.0 0.0 0.0 0.0 1.0 0.0 0.0 6.0 0Finally, I just pass the transformed object to RowAccessor.
PyTorch Foundation. PyTorch. The Linux Foundation, 2025, https://pytorch.org/.
PyTorch Foundation. "Datasets & DataLoaders." PyTorch Tutorials, The Linux Foundation, 16 Jan. 2024, https://docs.pytorch.org/tutorials/beginner/basics/data_tutorial.html.
Bansal, Puneet. Intel Image Classification. Kaggle, 2018, https://www.kaggle.com/datasets/puneet6060/intel-image-classification. Accessed 8 May 2025.
The pandas development team. pandas-dev/pandas: Pandas. Version 2.2.3, Zenodo, 20 Sept. 2024, https://doi.org/10.5281/zenodo.13819579.
"pandas.DataFrame." pandas Documentation, The pandas Development Team, 2025, https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html#pandas.DataFrame.
Brownlee, Jason. (2017). "Why One-Hot Encode Data in Machine Learning?". Machinelearningmastery. https://machinelearningmastery.com/why-one-hot-encode-data-in-machine-learning/